前言
本系列文章是 Deep Learning 的读书笔记,本书是深度学习极其优秀的学习参考书,有一定难度,因此本系列文章需要搭配原书一起阅读,效果更佳,如果不看原书,则假设你具有大学高等数学一般水平。
深度学习中的线性代数
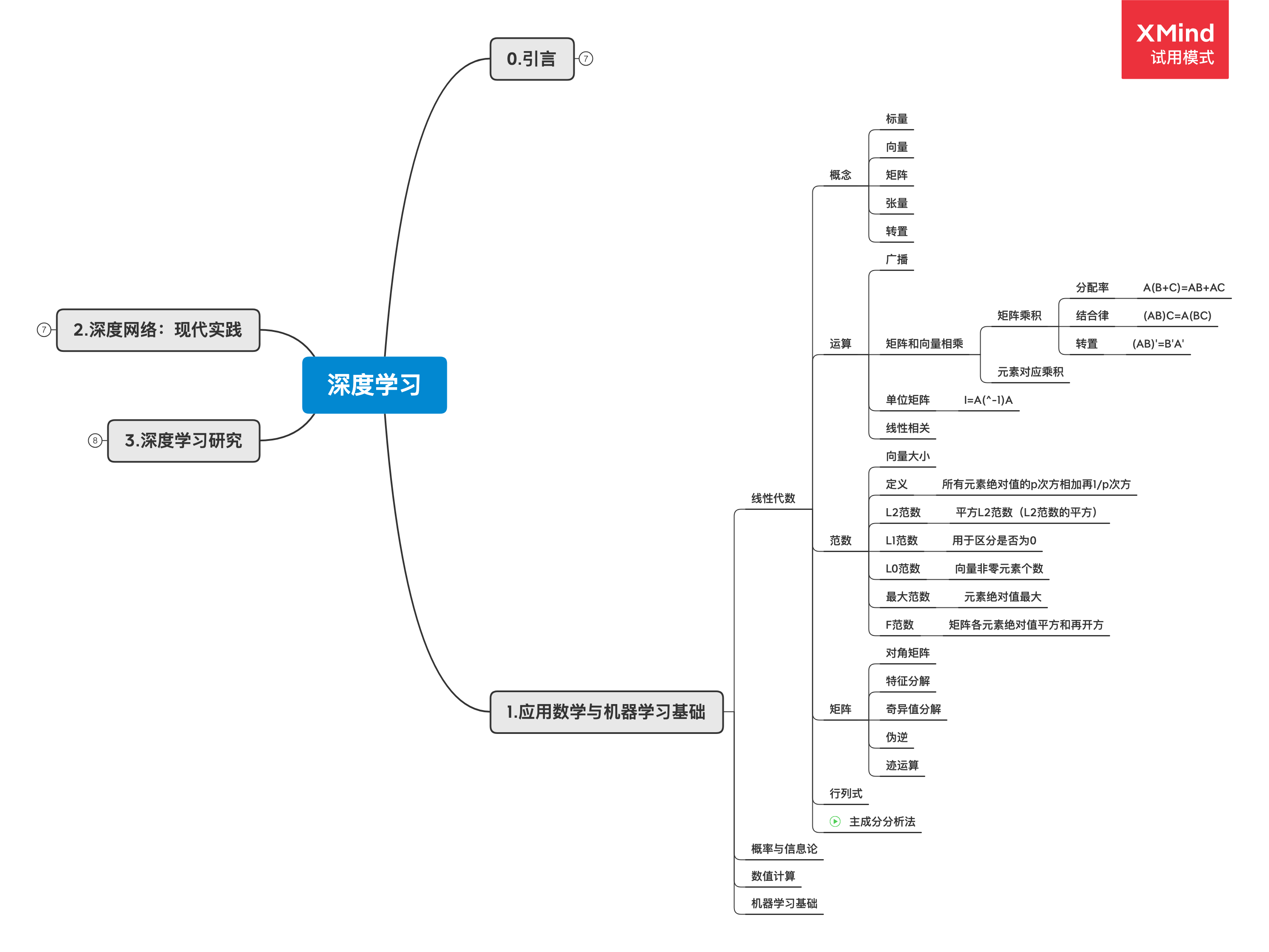
易混基础概念
- 标量:单独一个数
- 向量:一行/列数
- 矩阵:二维数组
- 张量:一般指多维(0 维张量是标量,1 维张量是向量,2 维张量是矩阵)
- 转置:沿主对角线折叠
在 Numpy 中定义矩阵的方法,以及进行转置的方法:
1 | import numpy as np |
基本算数关系
与高等数学中矩阵相乘内容一致:
1 | a = np.array([[1, 2], |
范数
范数是一个函数,用于衡量长度大小的一个函数。数学上,范数包括向量范数和矩阵范数。
向量范数
我们先讨论向量的范数。向量是有方向有大小的,这个大小就用范数来表示。
$$
形式上 L^p 范数:||x||_p=\left(\sum_i|x_i|^p\right)^{\frac{1}{p}}
$$
严格意义上来说,范数是满足下列性质的任意函数:
$$
\begin{cases}
{f(x)=0 => x=0}\\
{f(x+y)\leq{f(x)+f(y)}}\\
\bigvee\alpha\in{R},f(ax)=|a|f(x)
\end{cases}
$$
-
当 p=2 时,$L^2=||x||_2$范数(可简化写成||x||)称为欧几里得范数,可以用来计算距离。但是我们看到这里有一个开方运算,因此为了去掉这个开方,我们平时用的有可能是范数的平方,这就会减少一次开方运算,在后面提到的损失函数中,范数和平方范数都提供了相同的优化目标,因为范数的平方计算起来也更简单,因此平方范数更常用。
-
当 p=1 时,$L^1$范数是向量各元素绝对值之和,在机器学习领域,对于区分 0 和非 0 来说,$L^1$范数很好用。
-
当 p=0 时,$L^0$实际上不是一个范数,但是大多数提到范数的地方都会提到$L^0$,$L^0$用来表示这个向量中有多少个非 0 元素,它是非常有用的,在机器学习中的正则化和稀疏编码中有广泛应用。在一个例子中是这么说的:判断用户名和密码是否正确,用户名和密码是两个向量,$L^0=0$时,则登录成功,$L^0=1$时,用户名和密码有一个错误,$L_0=2$时,用户名和密码都错误。
-
当 p 为无穷大时,范数也被称为无穷范数、最大范数。表示向量中元素绝对值中最大的,$L^\infty=max(|x_1|, |x_2|, …, |x_n|)$。
矩阵范数
对于矩阵范数,我们只聊一聊 Frobenius 范数,简单点说就是矩阵中所有元素的平方和再开方,还有其他的定义方法,如下:
特殊类型的矩阵和向量
- 对角矩阵
- 对称矩阵
- 单位向量
- 正交矩阵
特征分解
λ 为特征值组成的特征向量。
- $Av=λv$
- $A=Vdiag(λ)V^{-1}$
- 对称矩阵:$A=QΛQ^T$,Q 为 A 的特征向量,Λ 是对角矩阵。
奇异值分解
我们熟悉特征分解,奇异分解与之类似:$A=UDV^T$(A:m x n,U:m x m,D:m x n,V:n x n)。U 和 V 正交,D 为对角矩阵。D 对角线上的元素称为 A 的奇异值。
求逆又是研究矩阵的非常好的方法,但因为奇异矩阵无法求逆,因此考虑退而求其次的方法,求其伪逆,这是最接近矩阵求逆的方法,把矩阵化为最舒服的形式去研究其他的性质,伪逆把矩阵化为主对角线上有秩那么多的非零元素,矩阵中其他的元素都是零。这也是统计学中常用的方法,在机器学习中非常好用。
线性代数的一些定义
- 对角矩阵:只有主对角线含有非零元素;
- 单位向量:具有单位范数的向量;
- 向量正交:如果两个向量都非零,则夹角 90 度;
- 标准正交:相互正交、$L^2$ 范数为 1;
- 正交矩阵:行向量和列向量分别标准正交;
- 特征分解:将矩阵分解为特征向量和特征值;
- 特征值和特征向量:Ax=λx 中的 λ 和 x;
- 正定、半正定、负定:特征值都正、非负、都负。
总结
线性代数的一大特点是“一大串”,统一的知识体系,相互之间紧密联系,非常漂亮,在深度学习中有重要的应用,还是应该要学好。
如果有必要,强烈建议听一遍课程,可以查看 这里,希望你学的开心!
