最近的股市震荡的有点厉害,跌的有点惨,面对如此情景,我波澜不惊,原因很简单,前几年我小试牛刀的时候我意识到了这不是我这种散户能玩得懂的,如今的我早已空仓。万物皆可 AI,如何用深度学习的方法去理解呢?当然,本篇不是一个指导买股票的文章,也不会用股票的数据信息去训练模型,我负不起这样的责任,也同样因为股票的市场行情远非一点股票价钱数据就可以解释的。下面我们来聊一聊正事,循环神经网络(RNN)。
为什么要引入循环神经网络?思考一个问题,如果问你明天股票的市场行情是看涨还是看跌,大概率你会搜索一下近一段时间的行情趋势,然后给我一个猜测的回答,我们认为明天的行情与近一段时间的股票价格是有关系的,我们人脑会对此进行一定的推测,我们知道神经网络在某一种程度上来说,也是一种模拟人脑的行为,那我们的神经网络可以做预测吗?我们之前用于训练卷积神经网络的是一个个独立的数据信息,我们把它们打乱顺序,猫和狗的图片顺序不重要,训练后还是可以得到正确的结果;但是很显然,股票的价钱信息是不能打乱顺序的,这两种数据有什么区别?
一种数据是顺序无关的,一种数据是顺序有关的。
我们之前的网络不好用了,我们需要新的网络去解决这个问题——循环神经网络。循环神经网络遍历数据时,会保存数据的状态信息,这个状态信息包含之前数据的信息,它的内部有环状结构,前一项数据项的输出,是下一个数据项的输入,这样后一项数据会受到前一项数据的影响。
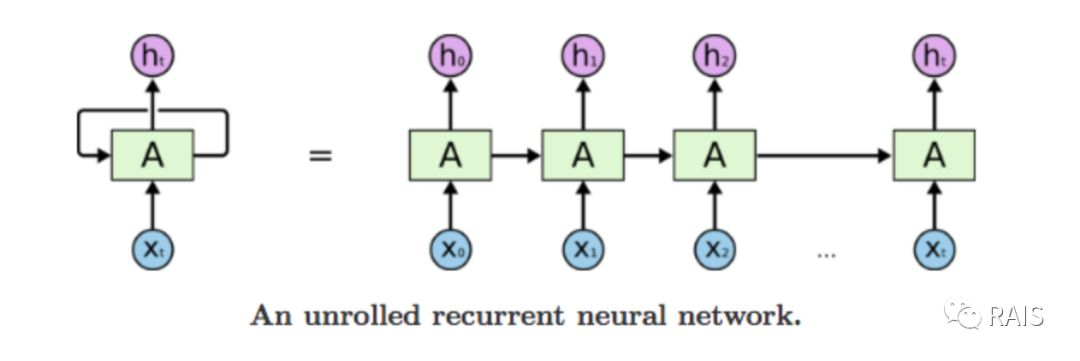
我们用一段矩阵处理的代码来解释这个问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| def deal():
timesteps = 100
input_features = 32
output_features = 64
inputs = np.random.random((timesteps, input_features))
print('input: ', inputs)
state_t = np.zeros((output_features,))
W = np.random.random((output_features, input_features))
U = np.random.random((output_features, output_features))
b = np.random.random((output_features,))
successive_outputs = []
for input_t in inputs:
output_t = np.tanh(np.dot(W, input_t) + np.dot(U, state_t) + b)
print(output_t)
successive_outputs.append(output_t)
state_t = output_t
final_output_sequence = np.stack(successive_outputs, axis=0)
print('output: ', final_output_sequence)
|
知道了原理,老规矩,我们还是用 Keras 实现,那种内置的实现,真是熟悉的味道,SimpleRNN。SimpleRNN 可以返回每一步输出的完整序列,也可以返回最终的结果,由 return_sequences 参数控制(True 时,返回完整序列),有了这样一个好用的循环神经网络,那我们就可以重新思考 IMDB 电影评论分类问题了。因为我们有了之前的经验,因此这一个的代码就很简单了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| def imdb_rnn():
max_features = 10000
maxlen = 500
(input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=max_features)
input_train = sequence.pad_sequences(input_train, maxlen=maxlen)
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(input_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
|
我们看看训练出来的结果:
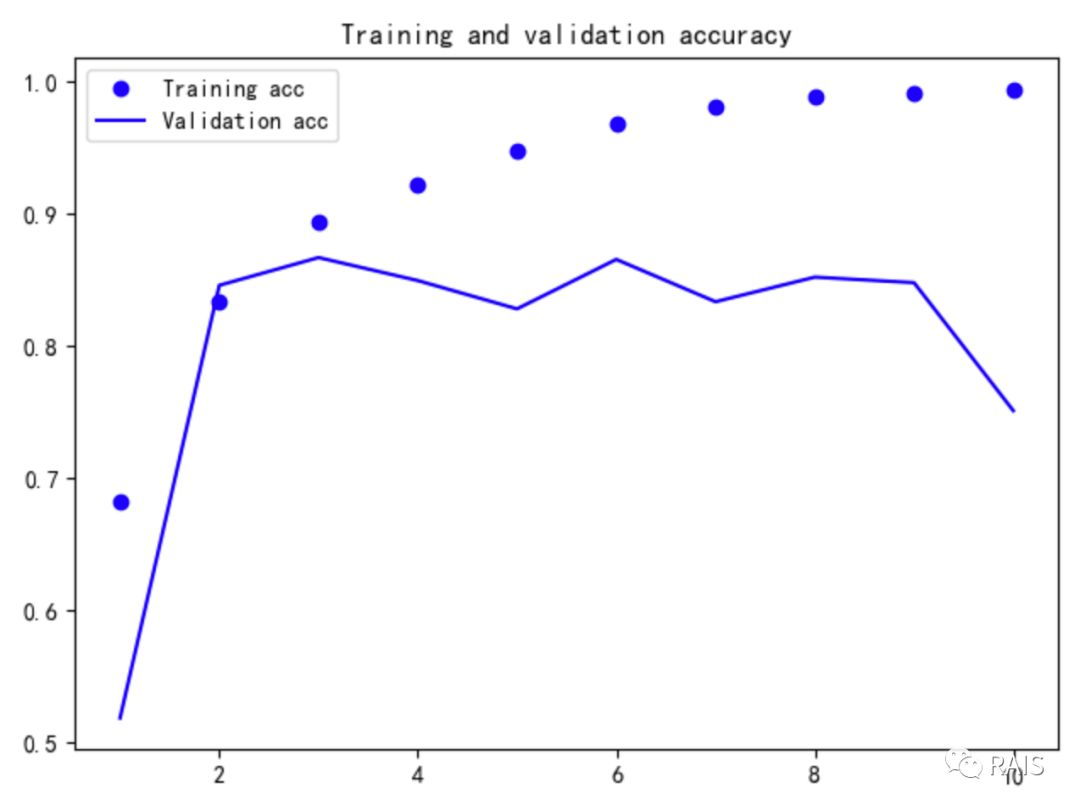
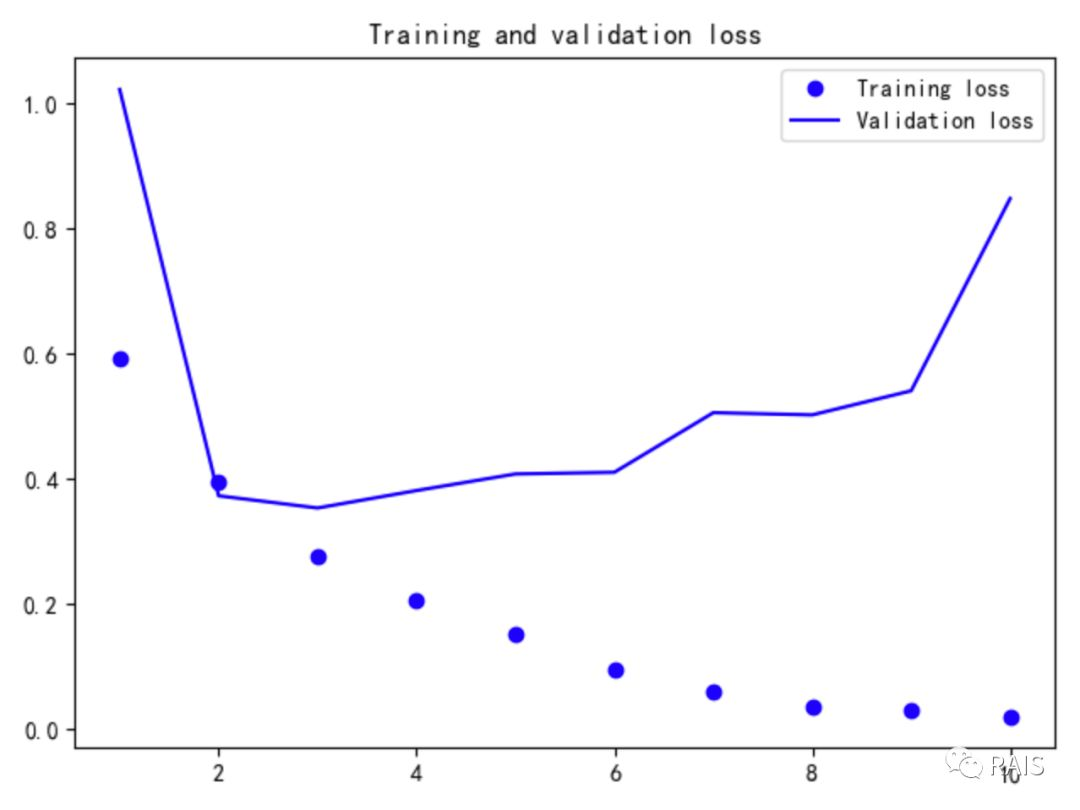
差不多 85% 的准确率,还算可以,毕竟我们只用了每条评论的前 500 个单词(我试着调大单词数目到 1000,时间延长了一点外,准确率却仅仅提高了 2%,有点得不偿失),为什么会出现这样的情况呢?原因是 SimpleRNN 的效果不好,那简单,换换其他的 RNN 方法吧。Keras 中还有 LSTM 和 GRU 这样的循环神经网络。
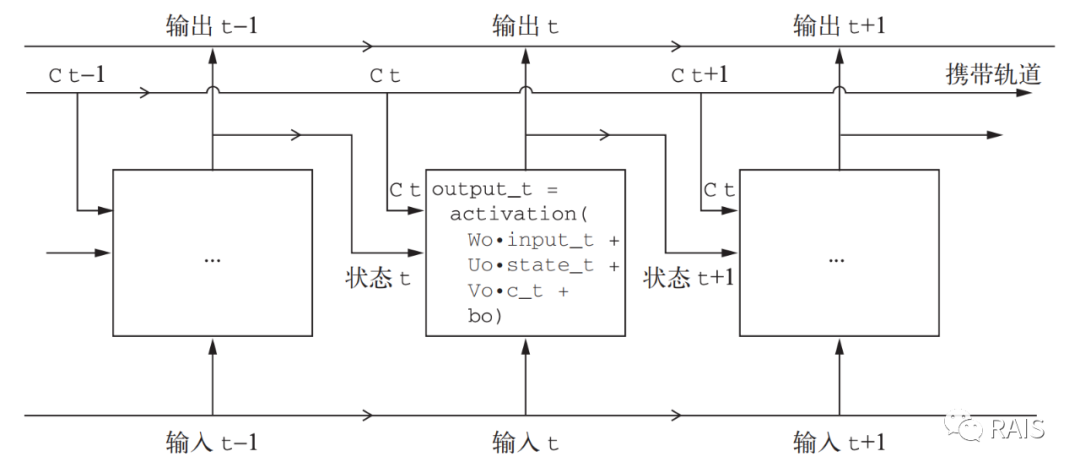
SimpleRNN 的一个问题是容易遗忘,专业点的术语叫做 梯度消失,数据在处理过程中,只记住了最近几步的信息,更早的信息淡忘了,相比具有更长期记忆的 LSTM 和 GRU 效果就好得多(这么说其实不准确,理论上仔细调整参数,SimpleRNN 是可以让有更好的长期记忆的,只是实践起来比较难,LSTM 不存在这样的问题)。比如 LSTM 的做法就是本次计算出来的结果不仅仅在下一次的计算中使用,而且被更长时间记忆,在更加靠后的计算中也能拿到这一次的计算结果,在某一种意义上来说,就是跨步骤传递信息,实现长期记忆了,这其中的细节信息当然是我们以后要具体讨论的,这里点到为止。
我们把上面 SimpleRNN 层换成 LSTM 层,代码已经在上面的注释中了,然后看看效果怎么样:
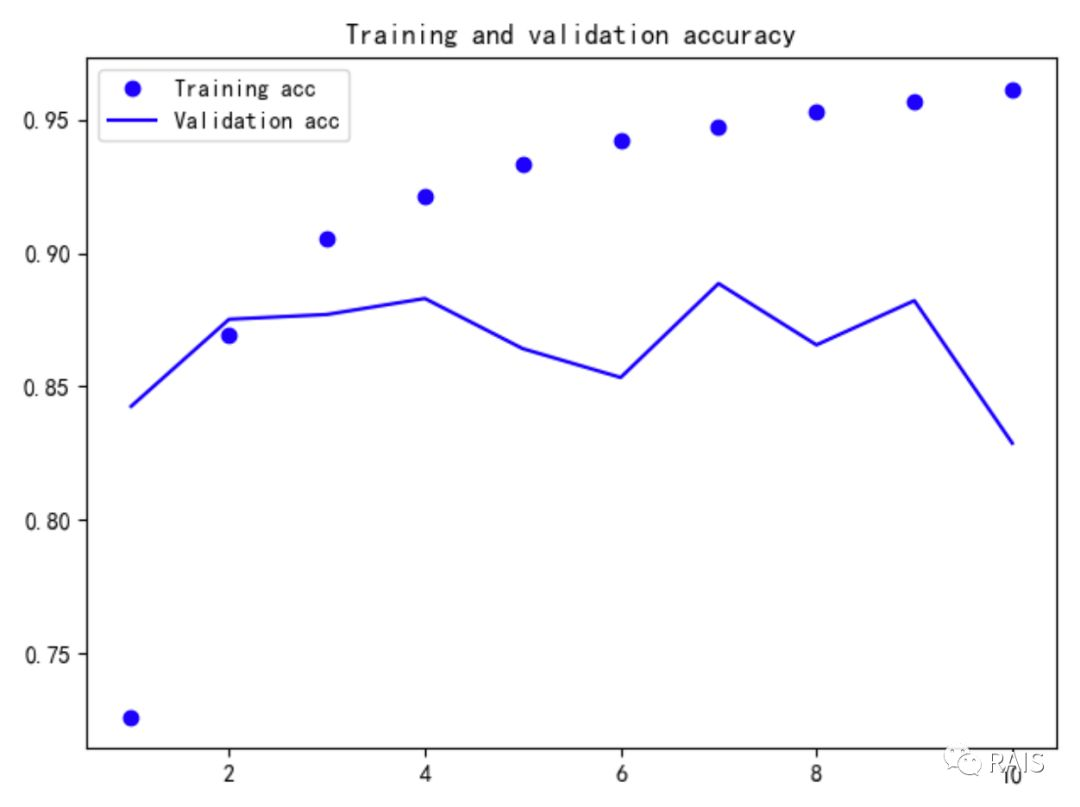
从这个我们可以看出来,百分之 90% 了,效果好了很多,对比一下我们之前用单词统计的方法训练的网络的结果(87% 左右),这里也是用了更少的数据,得到了更高的准确度,说明循环神经网络是有用的。在我们开心的同时,我们同样不要忽略一个问题,循环神经网络计算量更大了,这里的计算量增大了几倍,时间变长,换来的还是没有那么显著的提高,这样做真的是有意义的吗?针对这个问题,这其实跟我们的问题是有关系的,这个实际的问题是评论态度判断,其实在评论中,积极或者是消极的评论中,一些单词的出现其实是非常具有代表性的,“剧情无聊” 这样的词其实非常有说服力,因此对于这类问题,其实可以考虑用更大的数据量去训练网络,在计算量小得多的情况下,还能得到一个不错的结果。但是在其他场景,比如是一种聊天系统,或者是智能助手,循环神经网络的优势就会体现得更明显。
循环神经网络的基本内容我们就介绍的差不多了,下一次我们聊聊循环神经网络有哪些高级的用法。
推荐
